Design Unique ID Generator In Distributed Systems
Requirements Clarifications
- IDs should be unique
- IDs should be sortable by time
- IDs should be 64-bit size.
- The system should be able to handle 10,000 IDs per second
Multi-master replication
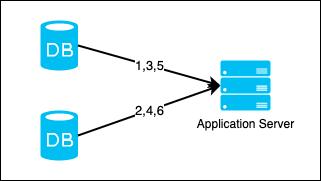
This approach make use of the databases’ auto_increment feature. We increase the ID in each server by step size k, where k is the number of database servers.
As illustrated in the image, the IDs generated increase by 2.
This approach has several drawbacks:
- Across multiple servers, IDs are not ordered by time
- Does not work well when adding or removing servers
Centralised Auto Increments
If we can’t make auto_increments work across multiple databases, what if we just use one database? This is the approach by Flickr.
A Flickr ticket server is a dedicated database server, with a single database on it, and in that database there are tables like Tickets32 for 32-bit IDs, and Tickets64 for 64-bit IDs.
The Tickets64 schema looks like:
CREATE TABLE `Tickets64` (
`id` bigint(20) unsigned NOT NULL auto_increment,
`stub` char(1) NOT NULL default '',
PRIMARY KEY (`id`),
UNIQUE KEY `stub` (`stub`)
) ENGINE=InnoDB
SELECT * from Tickets64 returns a single row that looks something like:
+-------------------+------+
| id | stub |
+-------------------+------+
| 72157623227190423 | a |
+-------------------+------+
When I need a new globally unique 64-bit ID I issue the following SQL:
REPLACE INTO Tickets64 (stub) VALUES ('a');
SELECT LAST_INSERT_ID();
This approach has several drawbacks:
- Single point of failure
UUID
String generateID() {
return UUID.randomUUID().toString().replaceAll("-","");
}
UUIDs are 128-bit hexadecimal numbers. They are easy to use and has a very low probability of collision. The system can scale very easily because each server is responsible for their own ID generation.
This approach has several drawbacks:
- Does not meet requirement of 64-bits size
- IDs are not ordered by time
Twitter Snowflake
This approach divides the ID into different sections.
| 1 bit | 41 bits | 5 bits | 5 bits | 12 bits |
|---|---|---|---|---|
| 0 | timestamp | data center id | machine id | sequence number |
The IDs are made up of the following components:
- Epoch timestamp - 41 bits which gives us 69 years for any custom epoch.
- Data Center ID - 5 bits which gives us 32 data centers
- Machine ID - 5 bits which gives us 32 machines per data centers
- Sequence number - Sequence number is incremented by 1 for every ID generated on the machine. Resets to 0 every millisecond. In theory, we can support 2^12 = 4096 new IDs every millisecond.
- The extra one reserved bit is to make the overall number positive.
This approach meets our requirements, however there are still several considerations:
- Clock synchronization. In distributed systems, servers may not use the same clock to generate the timestamp. Popular solution to clock synchronization may be to use Network Time Protocol.